Contexte
Afin de classer numériquement mes documents, je les scan et je leur donne le pattern suivant: <TYPE>-<PREFIX>-<DATE>-<SUFFIX>.pdf. Le processus manuel s’avère fastidieux car l’affichage pour traitement manuel est lent et il faut parfois ouvrir le document pour trouver les informations.
L’idée
Il y a quelques mois, j’avais essayé de l’OCR via LLM pour automatiser ce traitement, mais les coûts potentiels pour un usage personnel, ainsi que la protection de mes données ont stoppé net mes ambitions.
Il y a quelques semaines, j’ai eu l’idée de changer d’approche après avoir validé manuellement deux options:
- Avec une méthode traditionnelle d’OCR, il est possible d’extraire le contenu text de documents PDF scanné.
- Avec les AI Tools d’Infomaniak (https://ai-tools.infomaniak.com/), j’ai pu confirmer qu’avec un prompt adapté, mistral 3 est capable de répondre à mon besoin, à savoir, donner le nom du fichier souhaité à partir d’un extrait de la première page du PDF OCRisé. Ceci à un coût défiant toutes concurrences: après une centaine de documents traités, j’ai une facture de 2 centimes !
Automatiser ?
Il fallait maintenant assembler ces briques pour un premier traitement simple: renommer automatiquement mes fichiers selon le pattern souhaité.
Après avoir effectué quelques recherche, n8n community m’a semblé adapté car disponible gratuitement pour utilisation dans une image docker et devrait supporter l’appel à des LLM respectant l’API ChatGPT.
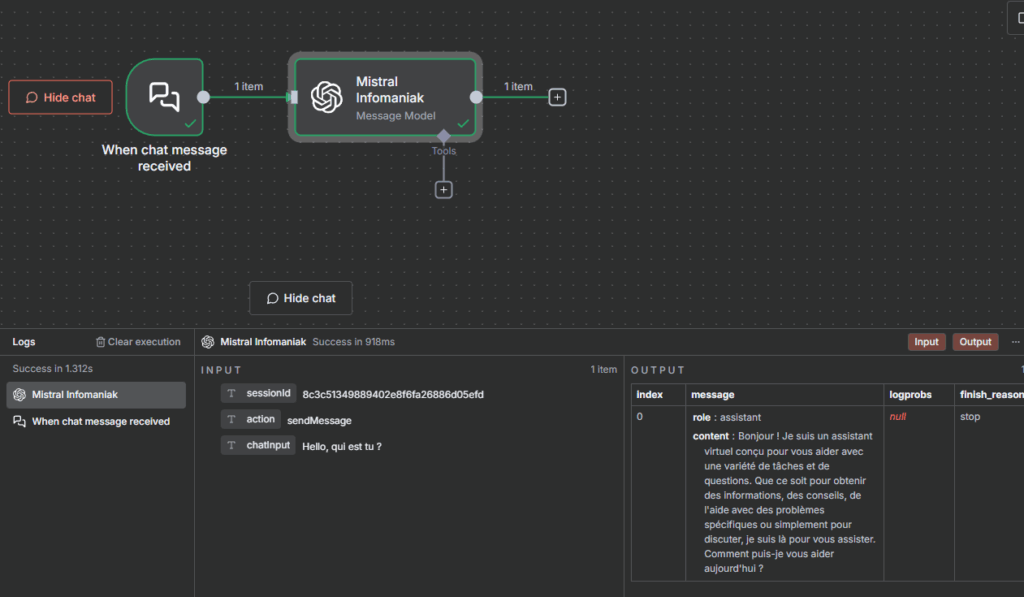
J’ai donc commencé à faire quelques tests pour vérifier qu’il était bien possible d’appeler un modèle chez Infomaniak depuis n8n. Et ça fonctionne :
S’en est suivie l’exploration de la conception de workflows sur n8n: ce n’est pas très complexe et on trouve énormément d’exemples et d’explications.
Ce qui a le plus posé de problèmes, c’est le traitement de fichiers locaux ainsi que l’exécution de mon script python d’OCR.
1. Script d’OCR
Le script fonctionnant sans problème en local, a pris beaucoup de temps pour être fonctionnel sur l’image docker n8n. J’ai rapidement créé une image personnalisée avec les librairies requises: pdf2image, pytesseract, spacy… mais impossible de faire fonctionner mon script.
Après plusieurs recherches, j’ai constaté que la fonctionnalité d’exécution de code python proposée sur n8n ne permettait pas d’installer n’importe quel module car il repose sur Pyodide: https://pyodide.org/en/stable/
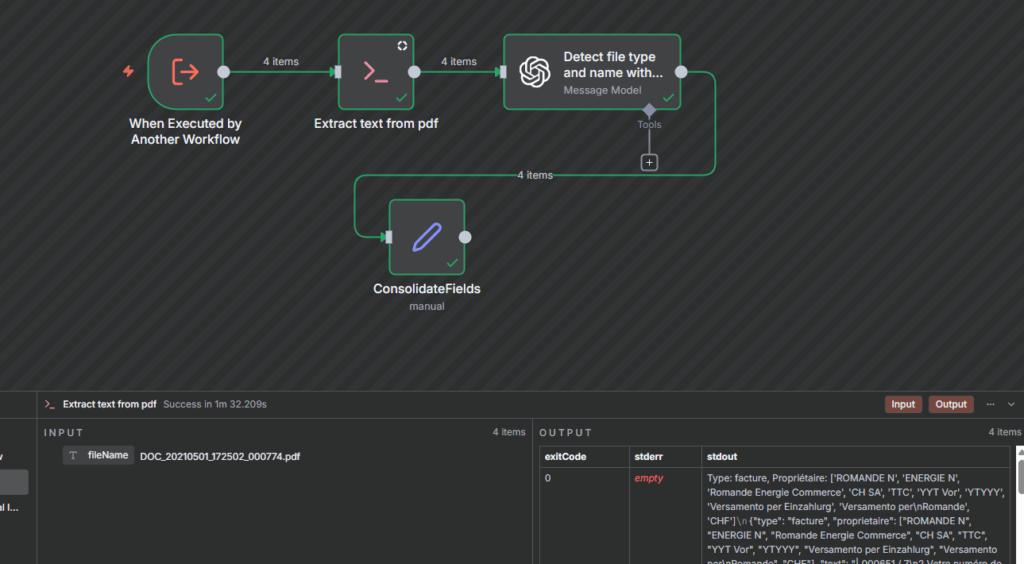
Restait alors l’option d’exécuter directement le script python via un noeud ‘Execute Command’:
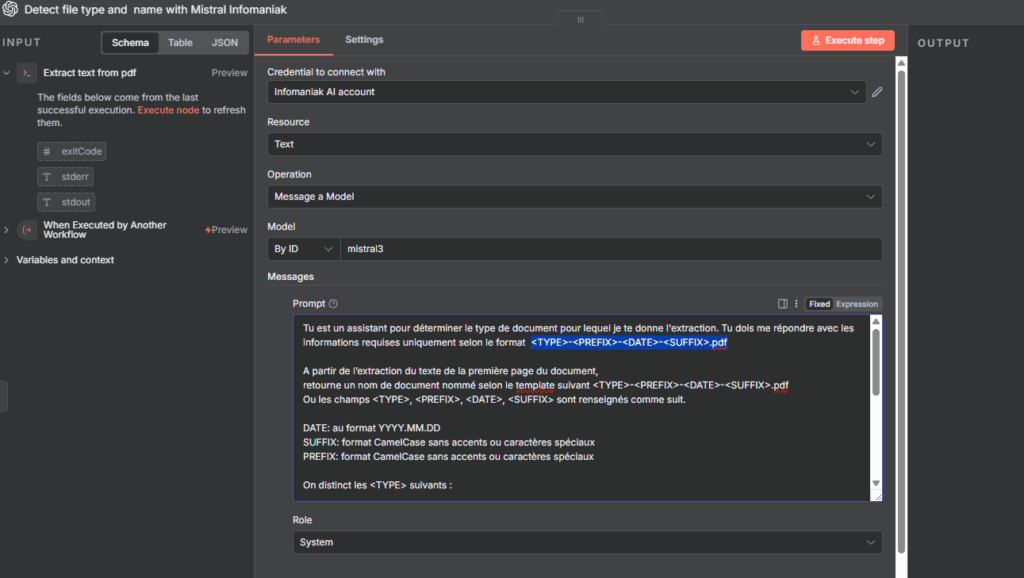
Une fois cette étape réglée, l’appel au modèle mistral 3 chez Infomaniak est une formalité:
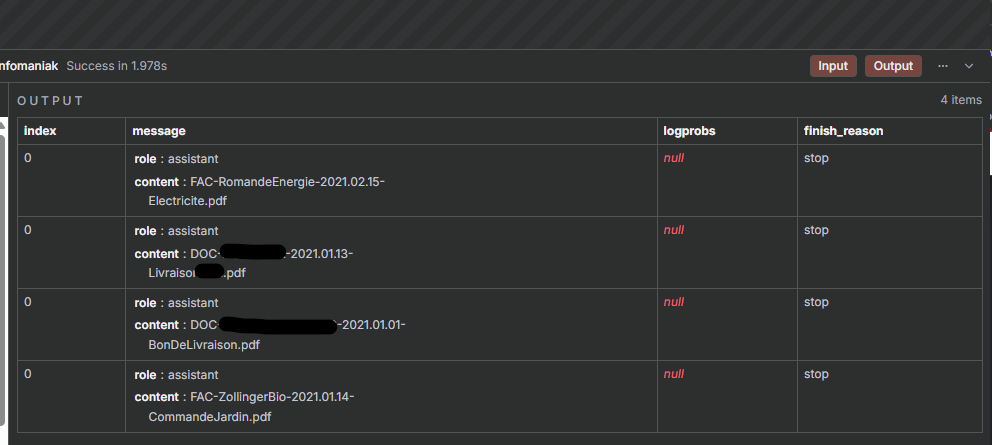
Exemple de résultats du traitement par mistral :
2. Fichiers locaux
Le traitement de fichiers locaux s’est avéré plus compliqué qu’attendu à cause de l’environnement Docker sur lequel n8n tourne: l’image n8n tourne avec l’utilisateur node(1000) qu’il faut « répliquer » sur l’hôte où tourne l’image.
Le résultat, un workflow manuel (pour l’instant) qui scan les fichier à traiter, itère par lot de 5 pour ocr-iser les pdf et les nommer avec l’aide de mistral 3 sur Infomaniak et un rapport fichierSource->fichierRenommé dans un CSV.
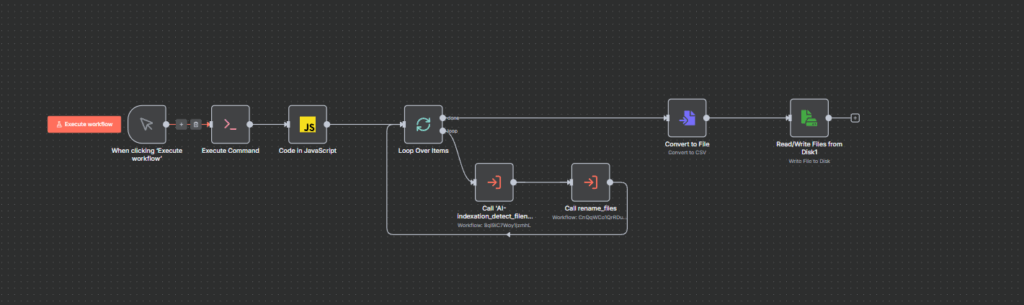
Conclusion
Si n8n peut être moins « user-friendly » que d’autres solutions similaires, il propose un grand nombre de « noeuds » et supporte surtout des LLM autres que Claude ou ChatGPT sur OpenAI.
J’avais accumulé pas mal d’idées d’automatisation par LLM, certaines floues, d’autres plus nettes, mais aucune ne répondait vraiment à un besoin concret chez moi. Maintenant, j’en ai trouvé une.
Ce workflow va certainement encore évoluer maintenant que j’ai pris en main l’outil.
Lien vers l’image n8n utilisée: https://github.com/fludo/n8n-py-addons/tree/main / https://hub.docker.com/repository/docker/swissmountain/n8n-py-addons/general